redis缓存服务器的原理实现和开发
2022-07-25 08:28 浏览: 次一、什么是redis
其中对redis,我们通常用Jedis(也为我们提供了连接池JedisPool)。
在redis中,key就是byteredis的数据结构(value):
String、list、set、orderset、hash
二、为什么快
1、纯内存操作
数据存放在内存中,内存的响应时间大约是 100纳秒 ,这是Redis每秒万亿级别访问的重要基础。
2、单线程操作,避免了频繁的上下文切换
虽然是采用单线程,但是单线程避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗 CPU;虽然作者认为CPU不是瓶颈,内存与网络带宽才是。但实际测试时并非如此,见上。
3、采用了非阻塞I/O多路复用机制
多路I/O复用模型是利用 select、poll、epoll 可以同时监察多个流的 I/O 事件的能力,在空闲的时候,会把当前线程阻塞掉,当有一个或多个流有 I/O 事件时,就从阻塞态中唤醒,于是程序就会轮询一遍所有的流(epoll 是只轮询那些真正发出了事件的流),并且只依次顺序的处理就绪的流,这种做法就避免了大量的无用操作。这里“多路”指的是多个网络连接,“复用”指的是复用同一个线程。加上Redis自身的事件处理模型将epoll中的连接,读写,关闭都转换为了事件,不在I/O上浪费过多的时间。
4、纯ANSI C编写
不依赖第三方类库,没有像memcached那样使用libevent,因为libevent迎合通用性而造成代码庞大,所以作者用libevent中两个文件修改实现了自己的epoll event loop。微软的兼容Windows补丁也因为同样原因被拒了。
快,原因之一是Redis多样的数据结构,每种结构只做自己爱做的事,当然比数据库只有Table,MongogoDB只有JSON一种结构快了。
三、I/O复用模型和Reactor 设计模式
详情请看:使用 libevent 和 libev 提高网络应用性能——I/O模型演进变化史
Redis内部实现采用epoll+自己实现的简单的事件框架。 epoll中的读、写、关闭、连接都转化成了事件,然后利用epoll的多路复用特性, 绝不在io上浪费一点时间:
1、I/O 多路复用的封装
I/O 多路复用其实是在单个线程中通过记录跟踪每一个sock(I/O流) 的状态来管理多个I/O流。
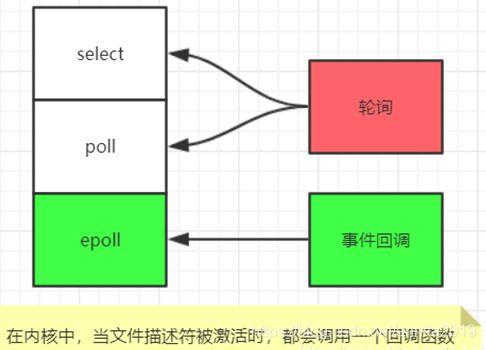
因为 Redis 需要在多个平台上运行,同时为了最大化执行的效率与性能,所以会根据编译平台的不同选择不同的 I/O 多路复用函数作为子模块,提供给上层统一的接口。
redis的多路复用, 提供了select, epoll, evport, kqueue几种选择,在编译的时候来选择一种。
select是POSIX提供的, 一般的操作系统都有支撑;
epoll 是LINUX系统内核提供支持的;
evport是Solaris系统内核提供支持的;
kqueue是Mac 系统提供支持的;
- #ifdef HAVE_EVPORT
- #include "ae_evport.c"
- #else
- #ifdef HAVE_EPOLL
- #include "ae_epoll.c"
- #else
- #ifdef HAVE_KQUEUE
- #include "ae_kqueue.c"
- #else
- #include "ae_select.c"
- #endif
- #endif
- #endif
为了将所有 IO 复用统一,Redis 为所有 IO 复用统一了类型名 aeApiState,对于 epoll 而言,类型成员就是调用 epoll_wait所需要的参数
接下来就是一些对epoll接口的封装了:
包括创建 epoll(epoll_create)
注册事件(epoll_ctl)
删除事件(epoll_ctl)
阻塞监听(epoll_wait)等
创建 epoll 就是简单的为 aeApiState 申请内存空间,然后将返回的指针保存在事件驱动循环中,注册事件和删除事件就是对 epoll_ctl 的封装,根据操作不同选择不同的参数,阻塞监听是对 epoll_wait 的封装,在返回后将激活的事件保存在事件驱动中。
2、Reactor 设计模式:事件驱动循环流程
Redis 服务采用 Reactor 的方式来实现文件事件处理器(每一个网络连接其实都对应一个文件描述符)
当 main 函数初始化工作完成后,就需要进行事件驱动循环,而在循环中,会调用 IO 复用函数进行监听
在初始化完成后,main 函数调用了 aeMain 函数,传入的参数就是服务器的事件驱动
Redis 对于时间事件是采用链表的形式记录的,这导致每次寻找最早超时的那个事件都需要遍历整个链表,容易造成性能瓶颈。而 libevent 是采用最小堆记录时间事件,寻找最早超时事件只需要 O(1) 的复杂度。
通过Reactor的方式,可以将用户线程轮询IO操作状态的工作统一交给handle_events事件循环进行处理。
用户线程注册事件处理器之后可以继续执行做其他的工作(异步),而Reactor线程负责调用内核的select/epoll函数检查socket状态。当有socket被激活时,则通知相应的用户线程(或执行用户线程的回调函数),执行handle_event进行数据读取、处理的工作。由于select/epoll函数是阻塞的,因此多路IO复用模型也被称为异步阻塞IO模型。注意,这里的所说的阻塞是指select函数执行时线程被阻塞,而不是指socket。一般在使用IO多路复用模型时,socket都是设置为NONBLOCK的,不过这并不会产生影响,因为用户发起IO请求时,数据已经到达了,用户线程一定不会被阻塞。
3、redis线程模型:
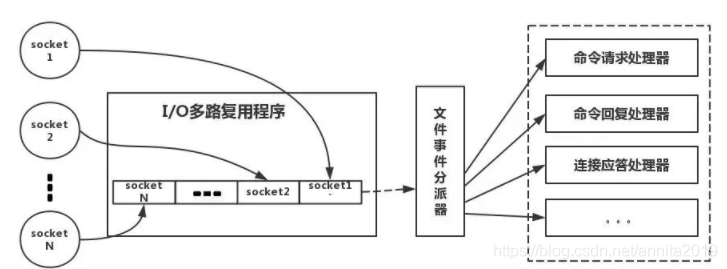
简单来说,就是。我们的redis-client在操作的时候,会产生具有不同事件类型的socket。在服务端,有一段I/0多路复用程序,将其置入队列之中。然后,IO事件分派器,依次去队列中取,转发到不同的事件处理器中。
四、redis的持久化方式:
能,将内存中的数据异步写入硬盘中,两种方式:RDB(默认)和AOF
1、RDB持久化原理
通过bgsave命令触发,然后父进程执行fork操作创建子进程,子进程创建RDB文件,根据父进程内存生成临时快照文件,完成后对原有文件进行原子替换(定时一次性将所有数据进行快照生成一份副本存储在硬盘中)
优点:是一个紧凑压缩的二进制文件,Redis加载RDB恢复数据远远快于AOF的方式。
缺点:由于每次生成RDB开销较大,非实时持久化,
2、AOF持久化原理
开启后,Redis每执行一个修改数据的命令,都会把这个命令添加到AOF文件中。
优点:实时持久化。
缺点:所以AOF文件体积逐渐变大,需要定期执行重写操作来降低文件体积,加载慢
五、redis主挂了怎么操作
redis提供了哨兵模式,当主挂了,可以选举其他的进行代替,哨兵模式的实现原理,就是三个定时任务监控。
每隔10s,每个S节点(哨兵节点)会向主节点和从节点发送info命令获取最新的拓扑结构
每隔2s,每个S节点会向某频道上发送该S节点对于主节点的判断以及当前Sl节点的信息,同时每个Sentinel节点也会订阅该频道,来了解其他S节点以及它们对主节点的判断(做客观下线依据)
每隔1s,每个S节点会向主节点、从节点、其余S节点发送一条ping命令做一次心跳检测(心跳检测机制),来确认这些节点当前是否可达
当三次心跳检测之后,就会进行投票,当超过半数以上的时候就会将该节点当做主。
六、redis集群
redis集群在3.0以后提供了ruby脚本进行搭建,引入了糙的概念,
Redis集群内节点通过ping/pong消息实现节点通信,消息不但可以传播节点槽信息,还可以传播其他状态如:主从状态、节点故障等。因此故障发现也是通过消息传播机制实现的,主要环节包括:主观下线(pfail)和客观下线(fail)
1、主客观下线:
主观下线:集群中每个节点都会定期向其他节点发送ping消息,接收节点回复pong消息作为响应。如果通信一直失败,则发送节点会把接收节点标记为主观下线(pfail)状态。
2、客观下线
超过半数,对该主节点做客观下线
主节点选举出某一主节点作为领导者,来进行故障转移。
故障转移(选举从节点作为新主节点)
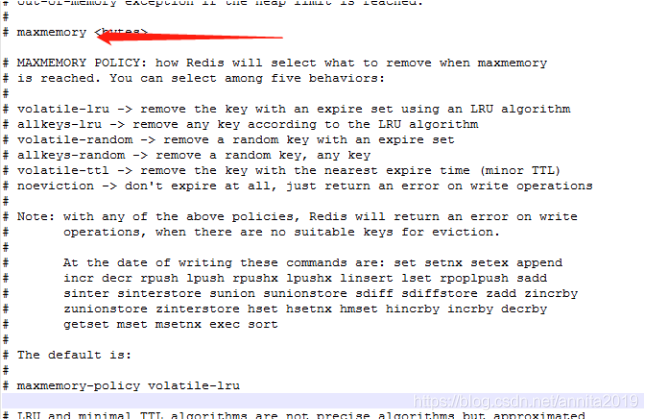
七、内存淘汰策略
Redis的内存淘汰策略是指在Redis的用于缓存的内存不足时,怎么处理需要新写入且需要申请额外空间的数据。
noeviction:当内存不足以容纳新写入数据时,新写入操作会报错。
allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key。
allkeys-random:当内存不足以容纳新写入数据时,在键空间中,随机移除某个key。
volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的key。
volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个key。
volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的key优先移除。
九、缓存击穿的解决方案:
原因:
就是别人请求数据的时候,很多数据在缓存中无法查询到,直接进入数据查询,
解决方法:
对相关数据进行查询的数据只查询缓存,如果是一些特殊的可以进行数据库查询,也可以采用布隆过滤器进行查询
十、缓存雪崩的解决方案:
缓存雪崩的原因:一次性加入缓存的数据过多,导致内存过高,从而影响内存的使用导致服务宕机
解决方法:
redis集群,通过集群方式将数据放置
后端服务降级和限流:当一个接口请求次数过多,那么就会添加过多数据,可以对服务进行限流,限制访问的数量,这样就可以减少问题的出现
【免责声明】:部分内容、图片来源于互联网,如有侵权请联系删除,QQ:228866015
 微信
微信 朋友圈
朋友圈 微博
微博 QQ空间
QQ空间


